Artificial Intelligence, particularly Generative AI, is rapidly evolving and becoming more accessible to everyday users. With large language models (LLMs) such as GPT and LLaMA making waves, the desire to run these models locally on personal hardware is growing. This article will provide a simple guide on setting up Ollama—a tool for running LLMs locally—on machines with and without a GPU. Additionally, it will cover deploying OpenWebUI using Podman to enable a local graphical interface for Gen AI interactions.
What is Ollama?
Ollama is a platform that allows users to run LLMs locally without relying on cloud-based services. It is designed to be user-friendly and supports a variety of models. By running models locally, users can ensure greater privacy, reduce latency, and maintain control over their data.
Setting Up Ollama on a Machine
Ollama can be run on machines with or without a dedicated GPU. The following will outline the general steps for both configurations.
1. Prerequisites
Before proceeding, ensure you have the following:
- A system running Fedora or a compatible Linux distribution
- Podman installed (for OpenWebUI deployment)
- Sufficient disk space for storing models
For machines with GPUs, you will also need:
- NVIDIA GPU with CUDA support (for faster performance)
- Properly installed and configured NVIDIA drivers
2. Installing Ollama
Ollama can be installed with a one-line command:
Clik here to view.

curl -fsSL https://ollama.com/install.sh | sh
Once installed, verify that Ollama is correctly set up by running:
ollama --version
Running LLMs Locally
After setting up Ollama, you can download a preferred model and run it locally. Models can vary in size, so select one that fits your hardware’s capabilities. For example: I would personally use llama3.3 70B model. That is around 42GiB and might not fit everyone. There *is* a model for everyone, even for raspberrypis -YES. Please find one that you will be fit for your system here .
On machines without a GPU, Ollama will use CPU-based inference. While this is slower than GPU-based processing, it is still functional for basic tasks.
Once you are done, running ollama run <model_name> will work!
Clik here to view.

Deploying OpenWebUI with Podman
For users who prefer a graphical user interface (GUI) to interact with LLMs, OpenWebUI is a great option. The following command deploys OpenWebUI using Podman, ensuring a seamless local setup.
1. Downloading OpenWebUI Container
Start by pulling the OpenWebUI container image:
podman run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Clik here to view.

2. Running the OpenWebUI Container
Once the image is downloaded, running ; ensure by running podman ps to list the existing containers. Access the OpenWebUI interface by opening your web browser and navigating to localhost:8080
Clik here to view.
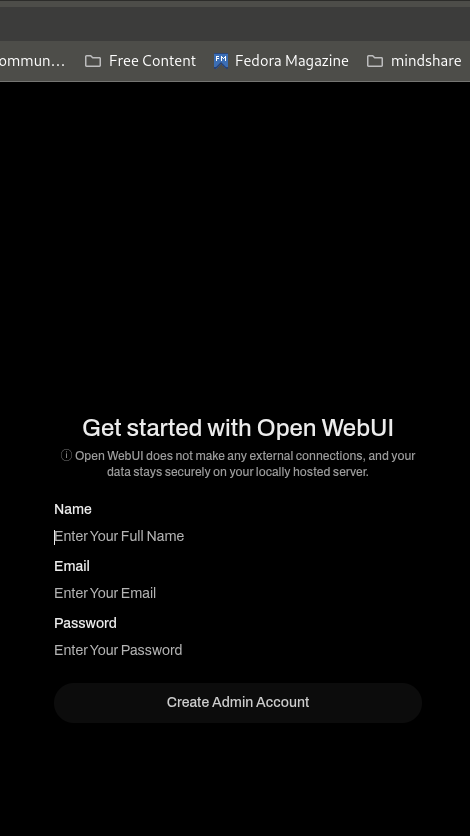
Open WebUI will help you create one or multiple Admin and User accounts to query LLMs. The functionality is more like an RBAC—you can choose to customize which model can be queried by which User and what type of generated responses it “should” be giving. The features help set guardrails for users who intend to provision accounts for a specific purpose.
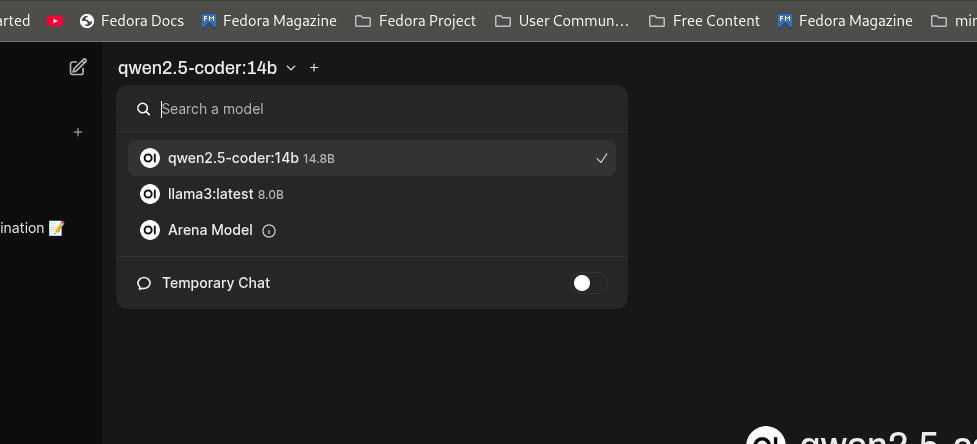
On the top-left, we should be able to select models. You can add more models by simply running ollama run <model_name> and then refreshing the localhost when the fetching is complete. It should let you add multiple models.
Clik here to view.
Interacting with the GUI
With OpenWebUI running, you can easily interact with LLMs through a browser-based GUI. This makes it simpler to input prompts, receive outputs, and fine-tune model settings.
Using LLaVA for Image Analysis
LLaVA (Large Language and Vision Assistant) is an extension of language models that integrates vision capabilities. This allows users to upload images and query the model about them. Below are the steps to run LLaVA locally and perform image analysis.
1. Pulling the LLaVA Container
Start by pulling the LLaVA model: ollama pull llava
2. Running LLaVA and Uploading an Image
Once the model is download, access the LLaVA interface via web UI on the browser. Upload an image and input a query, such as:
Clik here to view.

LLaVA will analyze the image and generate a response based on its visual content.
Other Use Cases
In addition to image analysis, models like LLaVA can be used for:
- Optical Character Recognition (OCR): Extract text from images and scanned documents.
- Multimodal Interaction: Combine text and image inputs for richer AI interactions.
- Visual QA: Answer specific questions about images, such as identifying landmarks or objects.
Conclusion
By following this how-to, you can set up a local environment for running generative AI models using Ollama and OpenWebUI. Whether you have a high-end GPU or just a CPU-based system, this setup allows you to explore AI capabilities without relying on the cloud. Running LLMs locally ensures better privacy, control, and flexibility—key factors for developers and enthusiasts alike.
Happy experimenting!